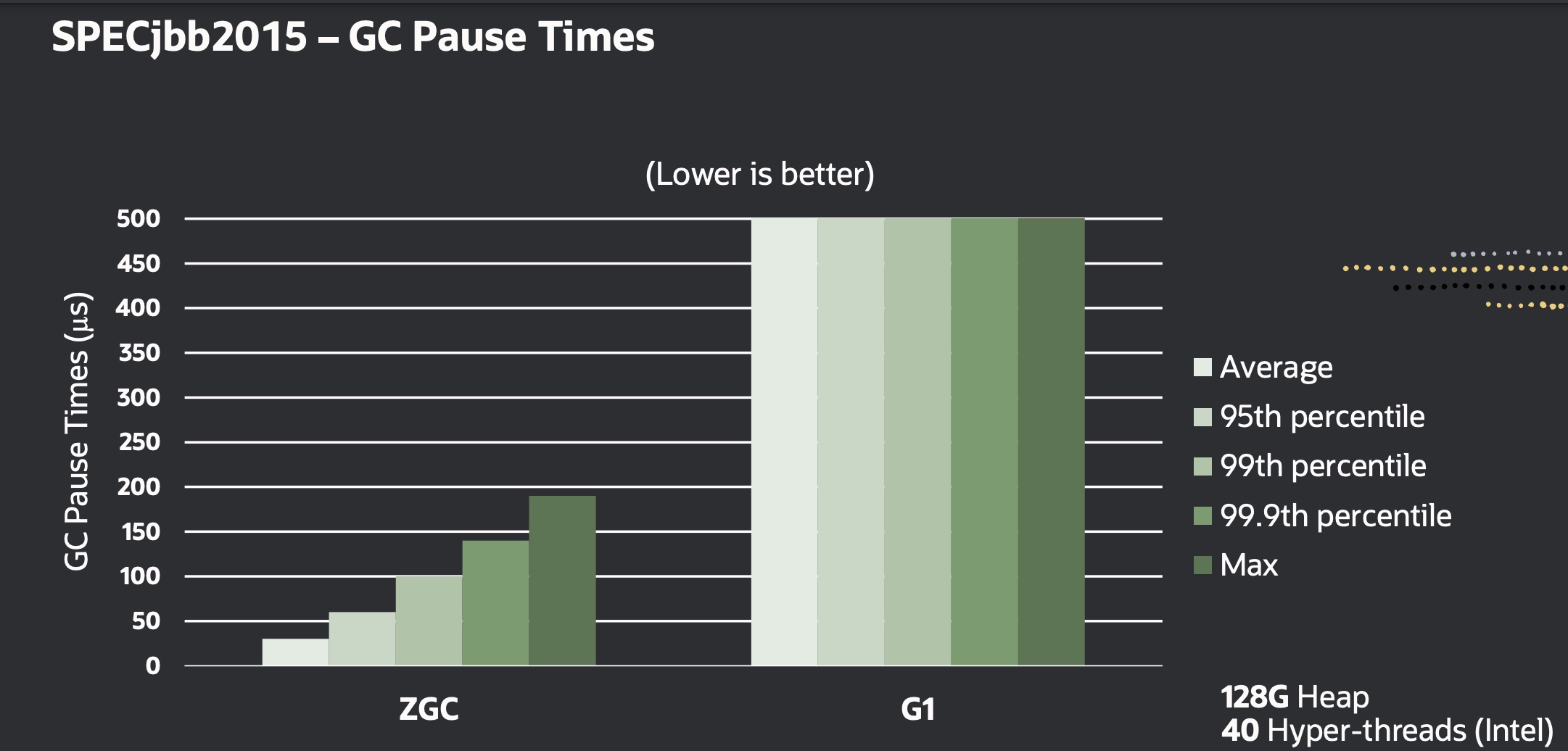
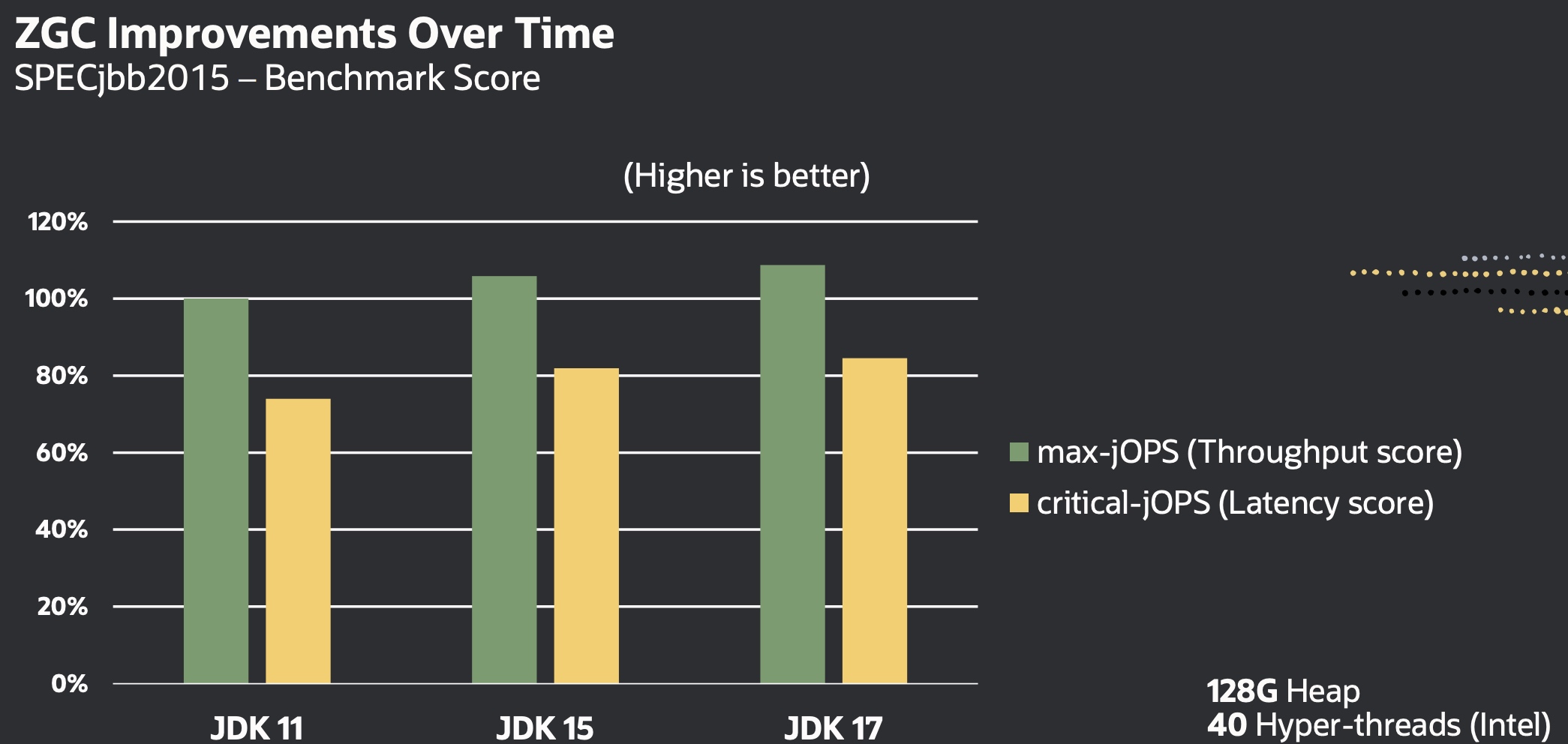
第5章:Pass和Passmanager MLIR中提供了变换(Transformation)和分析(Analysis)的概念,变换指的是将IR进行优化,生成新的IR(和方言降级略有不同,降级一般不涉及优化,仅仅简单的将某一算子变成一个或多个新类型的操作);而分析是提供一些信息供优化使用。本节主要讨论变换Pass,最后简单介绍分析管理。
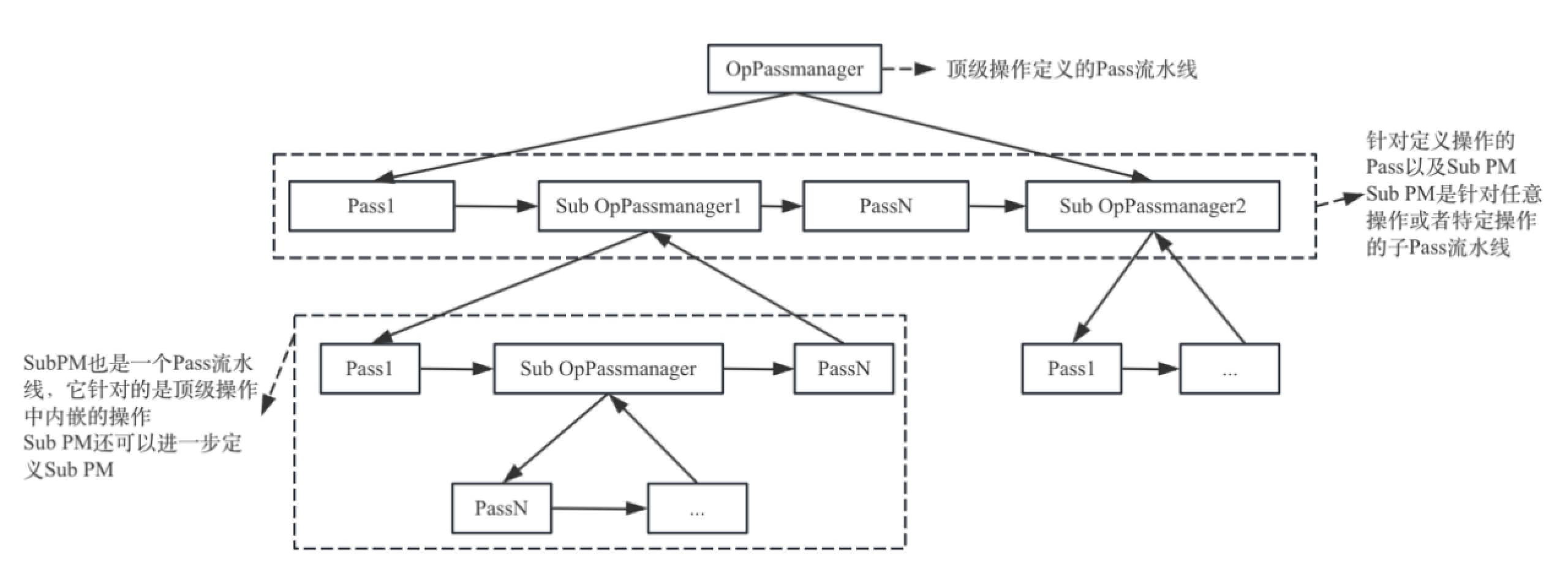
5.1Pass、Pass管理器和Pass流水线 MLIR框架提供Pass(遍)、Pass Pipeline(Pass流水线)、OpPassManager(操作Pass管理器)、PassManager(Pass管理器)等功能,方便开发者进行优化或者IR变换。其中Pass主要用于定义针对操作的变换,Pass Pipeline主要用于将多个Pass进行组合排布执行,而PassManager管理Pass和Pass Pipeline。为了方便统一管理Pass和Pass Pipeline,将Pass Pipeline设计为针对一个操作的多个Pass排布,通过OpPassManager结构进行管理(OpPassManager实际上继承于PassManager类型),这样OpPassManager也是针对一个操作,而一个一般的Pass也是针对一个操作,所以它们的地位相同,即它们又可以再次被组合成一个Pass Pipeline,由它们的共同父操作的OpPassManager进行管理。依此类推,所有的Pass可以构成一颗树。
本节将对Pass、Pass Pipeline、执行框架等注意展开介绍。
5.1.1Pass介绍 MLIR中变换的基础是操作。所以框架中定义了基类OperationPass,所有的Pass都继承于OpeartionPass,它有几个特点:
针对特定的操作进行处理;对于一般的Pass来说,如果没有指定操作则是针对任意操作进行处理,但是对于Pass Pipeline来说必须指定一些信息,其中包含要针对的操作,否则不能执行。
提供了一个接口canScheduleOn,用于判断Pass能否运行于特定的操作。
提供了一个接口getAnalysis,用于获取分析结果。
5.1.2Pass定义 Pass可以通过TD文件进行定义。TD中的记录PassBase约定了自定义Pass包括了哪些参数,PassBase对应的代码片段如代码5-1所示。
PassBase{ 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 //Pass的名字,在opt命令行中使用 String argument = passArg; //定义了Pass的基类,这个基类指的是C++类,通过是Operation String baseClass = base; //Pass的简单描述,这个描述体现在opt--help输出 String summary = ""; //Pass的完整描述,这个描述体现在自动生成的文档中 String description = ""; //Pass的构造函数,如果没有在TD文件中定义,则自动生成一个默认的函数签名 Code constructor=[{}]; //声明Pass依赖的的方言,只有在此处声明后的方言,才可以在该Pass中使用。 //该字段对应的函数为getDependentDialects,在该函数需要将方言注册到 //MLIRContext中,这样Pass才可以使用方言。 //如果没有注册方言,Pass使用相关方言会报错。 list<string> dependentDialects=[]; //Pass的参数 list<Option> options=[]; //Pass的统计信息,在统计Pass信息时使用。在TD文件中定义变量名、描述信息,就可以统计Pass的执行次数,并可以通过PassManager中的enableStatistics函数打开Pass执行次数统计,并在Pass执行结束后输出信息,在mlir-opt工具中可以通过参数mlir-pass-statistics直接使用。 list<Statistic> statistics=[]; }
开发者可能会对代码5-1中字段dependentDialects有一些疑问,为什么要在Pass中显式定义依赖的方言?而不是直接在MLIRContext中直接加载方言[ MLIR框架提供的一些工具例如mlir-opt、mlir-translate在开始执行前都会初始化MLIRContext,并注册相应的方言,否则MLIRContext在遍历IR时无法识别操作,就会报错。另外在变换时、方言降级时也需要依赖其它方言,因此早变换和降级过程会生成其它方言中的操作。]?首先要说明的是,Pass中可以使用的方言必须是MLIRContext已经加载过的方言,如果方言未加载则不能使用,如果使用则会报错(找不到对应方言)。
1 2 3 4 5 6 7 8 9 //Pass名字为affine-loop-invariant-code-motion //该Pass仅仅适用于操作类型为FuncOp def AffineLoopInvariantCodeMotion :Pass<"affine-loop-invariant-code-motion","func::FuncOp">{ //summary是简单描述 let summary="Hoist loop invariant instructions out side of affine loops"; //Pass的构造器,通过下面的函数构造C++对象 let constructor="mlir::createAffineLoopInvariantCodeMotionPass()"; }
通过工具mlir-tblgen翻译代码5-2,得到的记录如代码5-3所示。
AffineLoopInvariantCodeMotion{//记录的基类为Pass BasePass 1 2 3 4 5 6 7 8 9 string argument="affine-loop-invariant-code-motion"; string baseClass="::mlir::OperationPass<func::FuncOp>"; string summary="Hoist loop invariant instructions out side of affine loops"; String description=""; String constructor="mlir::affine::createAffineLoopInvariantCodeMotionPass()"; list<string> dependentDialects=[]; list<Option> options=[]; list<Statistic> statistics=[]; }
对照代码5-1非容容易理解代码5-3,继续使用mlir-tblgen运行代码5-3可以得到对应的C++文件,其中Pass定义相关的头文件如代码5-4所示。
DerivedT> 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 class AffineLoopInvariantCodeMotionBase : public ::mlir::OperationPass<func::FuncOp>{ public: Using Base = AffineLoopInvariantCodeMotionBase; //辅助类,用于定义Pass AffineLoopInvariantCodeMotionBase() : ::mlir::OperationPass<func::FuncOp>(::mlir::TypeID::get<DerivedT>()){} AffineLoopInvariantCodeMotionBase(const AffineLoopInvariantCodeMotionBase &other) : ::mlir::OperationPass<func::FuncOp>(other){} //Pass名字,在命令行通过该名字关联到Pass static const expr::llvm::StringLiteral getArgumentName(){ return ::llvm::StringLiteral("affine-loop-invariant-code-motion"); } ..... //支持LLVM开发体系中dyn_cast功能 static bool classof(const::mlir::Pass *pass){ return pass->getTypeID()==::mlir::TypeID::get<DerivedT>(); } ...... //Pass依赖的方言,此处为空 void getDependentDialects(::mlir::DialectRegistry®istry) const override{ } //定义C++对象的ID宏,用于标识对象 MLIR_DEFINE_EXPLICIT_INTERNAL_INLINE_TYPE_ID(AffineLoopInvariantCodeMotionBase<DerivedT>) };
代码5-4显式Pass继承于C++模板类mlir::OperationPass,这说明了MLIR中变换的基础是操作,所以框架中定义了模板类OperationPass。模板类是MLIR中Pass执行的基础框架部分。
1 2 3 def CSE:Pass<"cse">{ ... }
同样通过工具mlir-tblgen翻译代码5-5,忽略记录信息,直接看对应的C++如代码5-6所示。
1 2 3 4 5 template<typename DerivedT> class CSEBase : public ::mlir::OperationPass<>{ public: ... }
代码5-6中mlir::OperationPass<>是一个特殊的类,等价于参数为void,MLIR社区用这个类匹配任意的操作,也称为any操作。
pipelineBuilder(OpPassManager& pm){ 1 2 3 pm.addPass(std::make_unique<MyPass>()); pm.addPass(std::make_unique<MyOtherPass>()); }
从代码5-7中可以看出一个Pass Pipeline本质上就是一个OpPassManager。Pass和Pass pipeline的管理和执行由顶层的OpPassManager负责,为了简单,这里使用PassManager代替OpPassManager。PassManager首先将所有Pass、Pass pipeline中定义的依赖方言全部加载到PassManager中,只有加载过的方言才能被使用。
5.1.3Pass、Pass Pipeline注册 Pass和Pass Pipeline需要注册至MLIRContext后才能使用。在MLIRCnntext中Pass和Pipeline分别管理,它们各自由一个全局Map管理注册信息。在每个Pass和Pipeline中会调用框架中的函数mlir::registerPass和PassPipelineRegistration分别将Pass和Pipeline注册到全局变量中。在构造PassManager时将相关的Pass、Pipeline进行初始化。
Pass 1 2 3 4 5 inline void registerAffineLoopInvariantCodeMotion(){ ::mlir::registerPass([]()->std::unique_ptr<::mlir::Pass>{ return mlir::affine::createAffineLoopInvariantCodeMotionPass(); }); }
在代码5-8中,函数mlir::registerPass本质上通过一个全局变量管理所有注册的Pass,该变量是Map结构,其中key为TD文件中的passArg,表示pass的名字;而value为一个结构体,包含了(passArg,description,functor)其中passArg和key相同,description表示Pass的描述,而functor则是registerPass中参数,这个参数是一个函数指针,会调用Pass的构造器。
1 2 3 4 5 inline void registerAffinePasses(){ ... registerAffineLoopInvariantCodeMotion(); ... }
除了自动生成的代码外,开发者需要实现Pass的构造函数,用于构造一个Pass对象。实现过程中通常会定义一个类继承于上述自动生成的类,例如LoopInvariantCodeMotion继承于代码5-4中的AffineLoopInvariantCodeMotionBase,并且在Pass的构造函数中实例化对象,如代码5-10所示。
1 2 3 4 5 6 7 8 9 10 11 12 //runOnOperation函数MLIR框架调用 struct LoopInvariantCodeMotion : public affine::impl::AffineLoopInvariantCodeMotionBase< LoopInvariantCodeMotion>{ void runOnOperation()override; ... }; //创建Pass对象的函数 std::unique_ptr<OperationPass<func::FuncOp>> mlir::affine::createAffineLoopInvariantCodeMotionPass(){ return std::make_unique<LoopInvariantCodeMotion>(); }
代码5-10中最关键的函数为runOnOperation,这个函数在模板类模板类mlir::OperationPass为虚函数,需要开发者进行实现,并描述Pass真正的工作。
registerMyPasses(){ 1 2 3 4 5 6 7 //passPipelineRegistration接受一个functor,这个functor定义一个Pass Pipeline passPipelineRegistration<>( "argument","description",[](OpPassManager &pm){ pm.addPass(std::make_unique<MyPass>()); pm.addPass(std::make_unique<MyOtherPass>()); }); }
当完成Pass、Pass Pipeline注册后,就可以调用Pass或者Pass Pipeline。以mlir-opt工具为例,想要使用mlir-opt工具执行Pass,首先需要将Pass注册到mlir-opt工具(本节介绍注册函数),然后就可以通过mlir-opt工具执行Pass。例如MLIR框架中提供的mlir-opt工具中会调用registerAffinePasses,表示所有Affine相关的Pass都可以通过mlir-opt工具使用,当用户使用mlir-opt -affine-loop-invariant-code-motion命令就可以触发相关的Pass,并执行代码5-10中的runOnOperation函数。
5.1.4Pass执行顺序 看到在Pass定义的时候通常约定要处理的操作,这个操作也称为Pass的锚点,Pass的构造函数会返回模板类OperationPass和对应操作的实例,形如OperationPassfunc::FuncOp 的对象,这样的Pass称为特定Pass(op-specific)。也有一些Pass可以处理任意的操作,例如CSE,它继承于mlir::OperationPass<>,这样的Pass称为通用Pass(op-agnostic),它们的构造函数返回一个基类Pass的指针。
{ 1 2 3 4 5 6 spirv.module "Logical" "GLSL450"{ func @foo(){ ... } } }
代码5-12代码片段蕴含IR层级代码5-13所示。
1 2 3 `builtin.module` `spirv.module` `spirv.func`
对于代码5-13来说,定义的Pass Pipeline也应该按照这样的层级结构。官网提供了一个示例,如代码5-14所示。
1 2 3 4 5 6 7 8 9 10 11 12 auto pm = PassManager::on<ModuleOp>(ctx); //为最顶层PassManage添加Pass pm.addPass(std::make_unique<MyModulePass>()); //定义子Pass Pipeline OpPassManager &nestedModulePM = pm.nest<spirv::ModuleOp>(); nestedModulePM.addPass(std::make_unique<MySPIRVModulePass>()); //为子Pass Pipeline在定义子Pass Pipeline OpPassManager &nestedFunctionPM = nestedModulePM.nest<func::FuncOp>(); nestedFunctionPM.addPass(std::make_unique<MyFunctionPass>()); OpPassManager &nestedAnyPM=nestedModulePM.nestAny(); nestedAnyPM.addPass(createCanonicalizePass()); nestedAnyPM.addPass(createCSEPass());
代码5-14片段对应的Pass结构如代码5-15所示。
1 2 3 4 5 6 7 8 9 OpPassManager<ModuleOp> //最顶层的Pass Pipeline,只能处理ModuleOp MyModulePass OpPassManager<spirv::ModuleOp>//中间层Pass Pipeline MySPIRVModulePass OpPassManager<func::FuncOp>//最内层的Pass Pipeline MyFunctionPass OpPassManager<>//可以处理任意的操作 Canonicalizer CSE
图5-1描述的就是一种泛化的PassPipeline。
针对一个操作,将执行该Pass Pipeline下所有的可以运行的Pass;也就是说两个类型相同的操作,它们依次执行完各自可以运行的所有Pass[ 这样设计的目的是为了方便同一操作在不同Pass之间的数据复用。当然另一种执行Pass的方案是依次遍历Pass,针对一个Pass将所有需要执行的操作依次执行,这样的方案也是可以的,但可能对缓存不够友好。]。
如果Pass是OpPassManger,针对操作中的区域、基本块进行遍历,然后针对遍历的每一个操作寻找对应的Pass Pipeline,并执行。
5.1.5Pass实现的约束 Pass执行时针对操作进行处理,Pass框架在设计之初就确定了可以多线程执行,所以Pass实现需要遵守一定的规则,主要限制包括:
不得检查当前操作的同级操作的状态,不得访问嵌套在这些同级下的操作。因为其他线程可能正在并行修改这些操作。但是可以允许检查祖先/父操作的状态。
不得修改、删除当前操作下嵌套的操作以外的操作的状态。这包括从祖先/父块添加、修改或删除其他操作。同样是因为其他线程可能同时对这些操作进行操作。作为例外,当前操作的属性可以自由修改。这是修改当前操作的唯一方法(即不允许修改操作数等)。
不得在多个Pass的runOnOperation函数调用之间维护可变的状态。因为同一个Pass可以在许多不同的操作上运行,但执行时没有严格的执行顺序保证。当多线程处理时,特定的Pass实例甚至可能不会在IR内的所有操作上执行。因此,一个Pass的运行不应依赖于所处理的操作。
不得为Pass维护任何全局可变状态,包括使用静态变量。所有可变状态都应该由Pass的实例来维护。
Pass必须是可复制构造的,PassManager可以创建Pass的多个实例以便并行处理操作。
Pass针对的操作类型必须符合以下要求:操作必须被注册且被标记为IsolatedFromAbove特质[ 违反该要求,将得到形如trying to schedule a pass on an operation not marked as IsolatedFromAbove的错误。该约束本质上是说明Pass Pipeline中的Pass不能实现跨Pass间的优化。读者需要了解Pass的最小粒度,并非任意的操作都可以作为Pass的锚点。]。
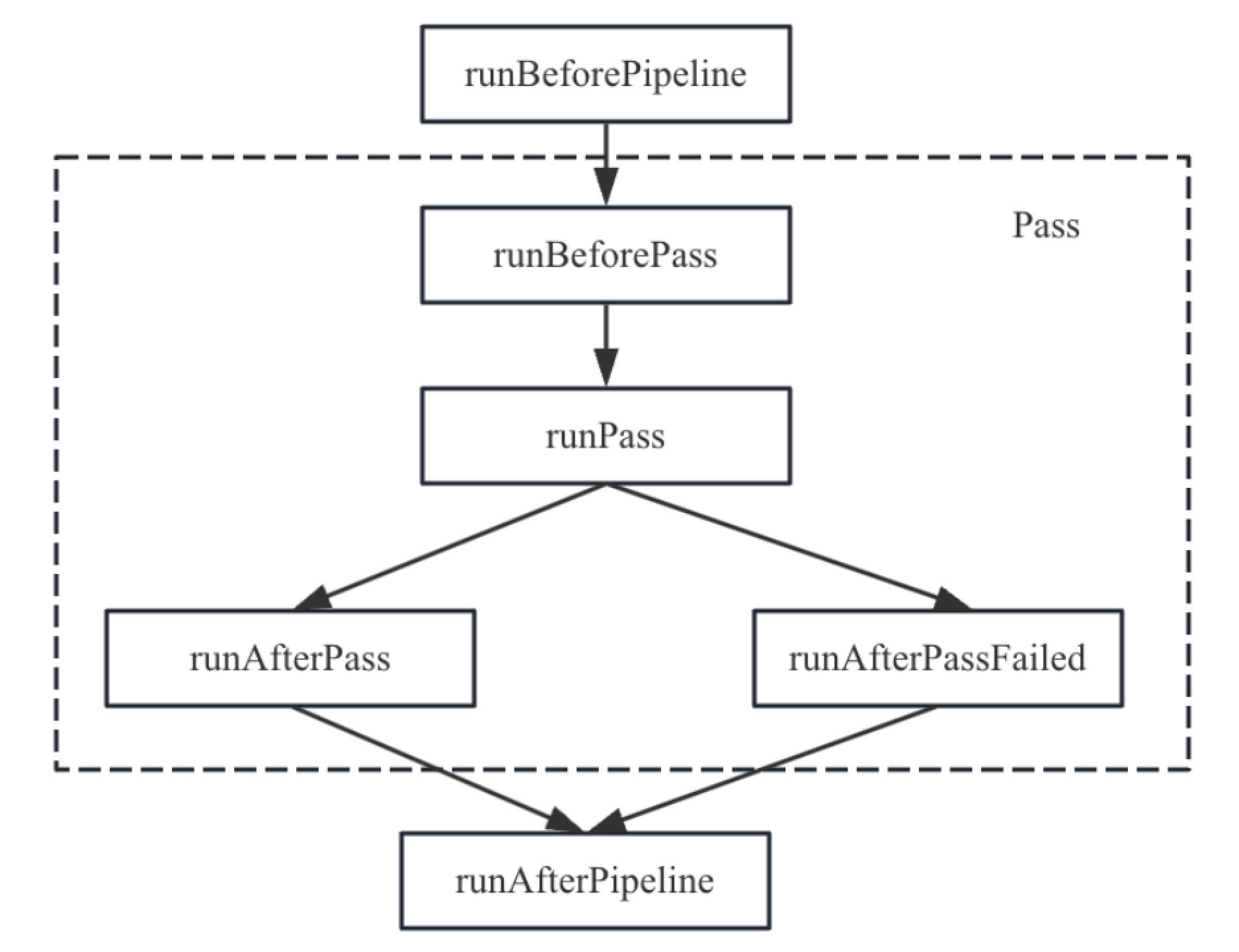
5.1.6Pass插桩机制 为了方便跟踪Pass的执行,MLIR框架针对Pass执行提供了插桩机制。该机制非常灵活,是一个可定制的插桩框架,通过类PassInstrumentation来检测Pass和分析计算的执行。类PassInstrumentation提供了PassManager的钩子函数来观察各种事件,这些钩子函数主要包括:
runBeforePipeline:该钩子函数在执行Pass Pipeline之前运行。
runAfterPipeline:无论Pass Pipeline执行成功与否,该钩子函数在执行Pass Pipeline执行后立即运行。
runBeforePass:该钩子函数在执行Pass之前运行。
runAfterPass:该钩子函数在Pass成功执行后立即运行。如果这个钩子被执行,则另一个钩子函数runAfterPassFailed不会执行。
runAfterPassFailed:该钩子函数在Pass执行失败后立即运行。如果这个钩子被执行,则另一个钩子函数runAfterPass不会执行。
runBeforeAnalysis:该钩子函数在分析计算之前运行。如果分析请求另一个分析作为依赖项,则可以从当前钩子函数对依赖的runBeforeAnalysis/runAfterAnalysis对进行调用。
runAfterAnalysis:该钩子函数在分析计算后立即运行。
而插桩中runBeforeAnalysis/runAfterAnalysis在Pass执行过程中获取分析结果时会被执行。钩子函数它对应的runAfter 钩子函数将是第一个被执行。类PassInstrumentation保证以线程安全的方式执行钩子函数,因此不需要额外的同步。下面给出一个示例Pass插桩,用于统计支配信息计算次数,由于支配信息计算是分析过程,所以Pass插桩要对分析相关的钩子函数进行实现,如代码5-16所示。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 //自定义Pass插桩 struct DominanceCounterInstrumentation : public PassInstrumentation{ //设计一个计数器,用于存储支配信息计算的次数 unsigned &count; DominanceCounterInstrumentation(unsigned &count):count(count){} //在分析计算后调用该钩子函数,如果分析是计算支配信息,则累加计数器 void runAfterAnalysis(llvm::StringRef,TypeID id,Operation*)override{ if( id == TypeID::get<DominanceInfo>()) ++count; } }; //下面是Pass插桩的使用示例,首先使用前需要找到对应的上下文 MLIRContext *ctx = ...; PassManager pm(ctx); //将Pass插桩注册到PassManager中 unsigned domInfoCount; pm.addInstrumentation(std::make_unique<DominanceCounterInstrumentation>(domInfoCount)); //遍历操作,运行PassManager ModuleOp m=...; if(failed(pm.run(m))) ... //运行完成后则可以通过参数domInfoCount获取全部支配信息的计算次数 llvm::errs() << "DominanceInfo was computed" << domInfoCount << "times!\n";
5.1.7标准插桩 Pass插桩是MLIR框架非常有用的功能,在MLIR社区提供了三个基于Pass插桩的有用实现,包括:时间统计、IR打印、Pass失败捕获。
1.时间统计 有一个常见的需求统计Pass执行时间信息,因此MLIR框架在类PassManager有一个函数enableTiming允许开发者针对PassManager统计Pass执行信息。例如mlir-opt工具就是利用该函数实现了Pass信息统计,在使用时通过给mlir-opt传递参数-mlir-timing即可。功能就是基于Pass插桩的能力实现,定义PassTming类,它继承于PassInstrumentation,并实现相关的钩子函数,在钩子函数runBefore中记录起始时间,在钩子函数runAfter 中获取结束时间,从而在PassManager运行结束后可以打印Pass的统计信息。
2.IR打印 IR打印也是利用Pass插桩功能,定义IRPrinterInstrumentation类,它继承于PassInstrumentation,并实现runBeforePass、runAfterPass、runAfterPassFailed截获执行的操作,输出操作,从而实现IR打印。基于这个Pass插桩,MLIR框架实现了和LLVM一样的IR输出。为了便于读者只关注关心的IR,MLIR社区还提供了一系列的参数控制IR打印的范围。常见的命令参数有:
mlir-print-ir-before:设置关注的Pass,在Pass运行之前打印IR。
mlir-print-ir-before-all:在每个Pass运行之前都打印IR。
mlir-print-ir-after:设置关注的Pass,在Pass运行之后打印IR。
mlir-print-ir-after-all:在每个Pass运行之后都打印IR。
mlir-print-ir-after-change:如果Pass改变了IR则在Pass执行后打印IR。该选项需要和mlir-print-ir-after或者mlir-print-ir-after-all配合使用。
mlir-print-ir-after-failure:在Pass执行失败后打印IR。
mlir-print-ir-module-scope:打印当前操作的顶层操作全部打印出来,该参数需要禁止Pass并发执行(需设置mlir-disable-threading)。
3.Pass执行失败捕获与重放机制 Pass在执行过程中可能发生错误,编译系统的输入可能包含了许多操作,而编译器过程中还可以应用多种Pass的组合,但是编译执行过程中可能遇到Pass失败的场景,而这时要准确定位到哪个Pass在对哪个操作处理时发生错误就非常困难。所以MLIR框架提供了Pass失败捕获机制以及重放机制。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 func.func @foo(){ %0=arith.constant 0:i32 return } func.func @bar(){ return } //下面重放,即针对上面的mlir通过下面的命令可以重现问题 {-# external_resources:{ mlir_reproducer:{ verify_each:true, pipeline:"builtin.module(func.func(cse, canonicalize{max-iterations=1 max-num-rewrites=-1 region-simplify=false top-down=false}))", disable_threading:true } } #-}
同时MLIR社区还提供了重放机制,例如在mlir-opt工具中通过参数-run-reprodcuer可以重新运行指定的操作和Pass Pipeline。这个功能的实现也比较简单,从mlir-reprodcuer中获取Pass Pipeline等信息,然后针对相应的操作执行Pass即可。
5.2分析和分析管理 与变换过程一样,分析也是一个重要的概念。它在概念上类似于变换过程,只不过分析仅仅计算特定操作的信息而不修改它。在MLIR中,分析不是Pass,而是独立的类,它们按需延迟计算并缓存以避免不必要的重新计算。也就说是MLIR中的分析需要先定义一个类,用于描述分析过程和分析结果,并在变换Pass中显式的生成分析对象以及调用分析过程。为了使用方便,MLIR引入了AnalysisManager,它仅仅管理分析对象。或者Operation 和AnalysisManager&为参数的构造函数进行构造(其中参数AnalysisManager用于查询分析依赖)。
getAnalysis<>:对当前操作进行分析,在必要时构建它,通常在构建分析对象时会进行分析。
getCachedAnalysis<>:获取当前操作的分析(如果已存在)。
getCachedParentAnalysis<>:获取给定父操作的分析(如果存在)。
getCachedChildAnalysis<>:获取给定子操作的分析(如果存在)。
getChildAnalysis<>:获取给定子操作的分析,在必要时构建它。
markAllAnalysesPreserved:保存所有的分析结果。
markAnalysesPreserved<>:保存指定类的分析结果。