全局指令选择算法介绍
SelectionDAGISel经过了多年的发展,功能完善且可靠性高。但是它存在着三个主要的问题。
- 1)SelectionDAGISel包含了过多的功能,比如许多的合并优化和合法化优化;还有为了降低编译时间,而增加的FastISel的算法。而这些功能大多跟指令选择算法本身不是强相关,但都被放入到指令选择中,导致其代码架构越来越繁复,代码维护的成本变高。
- 2)它是以基本块为粒度进行指令模式匹配,导致一些跨基本块的模式无法匹配上,增加了生成最优代码的难度。
- 3)DAG IR是图结构,需要一个指令调度的功能才能生成线性的MIR,这导致编译时间的增加。但是它的输入LLVM IR本身是线性结构,如果DAG IR不是图结构的,指令调度就可以去除掉。
由于这些问题都是当前SelectionDAGISel架构设计的问题,无法通过简单地修补进行完善。所以社区在2015年提出重新设计一套指令选择算法的想法,即全局指令选择(GlobalISel),期望能解决掉这些问题。
目前全局指令选择算法的基本已经开发完成,有一些指令架构已经在逐步适配(Aarch64/X86等)。本节下面会介绍这个算法的基本原理和功能模块。
7.4.1 全局指令选择概述
在图7-4中提到全局指令选择算法分成2个阶段来实现指令选择模块的功能。在全局指令选择中使用了一种新的中间表示是Generic Machine IR(GMIR)。全局指令选择第一阶段先将LLVM IR转成GMIR,在第二阶段将GMIR转成MIR。读者可能会问为什么要引入一种新的IR,而不是重用MIR?
首先GMIR IR是线性的IR,它和MIR共用数据结构,除了Opcode不同,指令表示方式等均是相同的(MIR的具体结构可以参考附录A.4)。GMIR的Opcode是一套架构无关的Opcode, 用于支持不同架构的指令转换。在全局指令选择的第一阶段,使用宏展开的算法,将LLVM IR转成GMIR,接着基于GMIR做指令合法化和寄存器类型分配。此外,在高优化级别的场景下,还会做一些合并类的窥孔优化。最后,全局指令选择的第二阶段使用表驱动的算法,生成相应的MIR。
另外,指令选择分成2个功能相对独立的阶段,但每个阶段的算法都比较复杂,所以为了避免过多功能耦合在一起造成代码复杂性过高,不利于代码维护和功能演进,全局指令选择采用了多Pass的设计,将2个阶段涉及的功能进行解耦,每个可以独立的功能都实现为单独的Pass。这样既使得整体架构更为清晰,同时能够方便利用LLVM Pass的相关基础设施(如dump等功能),进行代码维护和问题分析定位。
目前LLVM实现中将全局指令选择所必需的基本功能划分为4个Pass,其中第一阶段包含3个Pass,而第二阶段为一个Pass。还有窥孔类的优化也会以独立Pass进行实现,并可以放置在4个基础Pass之间的任意位置,不同的架构可以根据需要配置一到多个这种优化Pass。如图7-27所示。
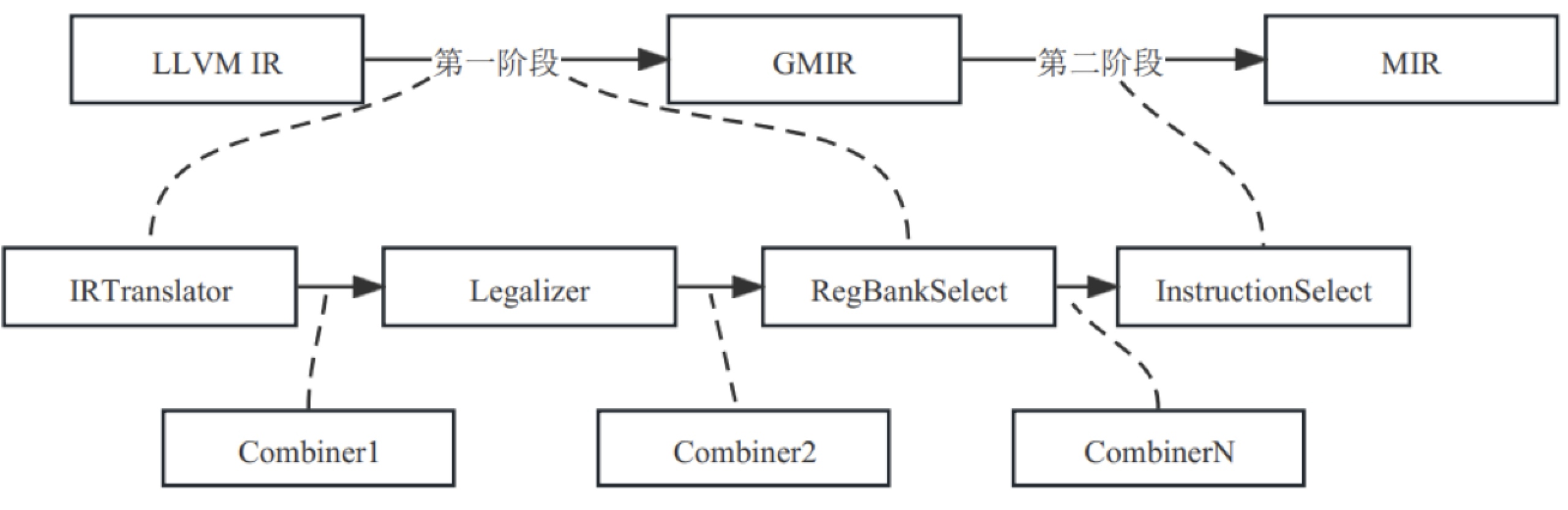
图7- 27 全局指令选择Pass示意图
第一个阶段的3个基础Pass分别是:
- IRTranslator:将LLVM IR转换为GMIR。
- Legalizer:将GMIR中一些目标架构不支持的GMIR指令替换为目标架构可以支持的GMIR指令序列。
- RegBankSelect:为GMIR中每个寄存器操作数分配合适的目标架构寄存器组类型。
第二阶段的Pass有: - InstructionSelect:将GMIR转换为目标架构相关的MIR。
除此以外,在指令选择的过程中还有一些优化类的Pass,如图7-27中Combiner1、Combiner2、CombinerN等,它们完成一些窥孔类型指令合并优化,提高生成代码的质量,它们可以由一到多个。
下面详细介绍每个功能的原理以及实现。
7.4.2 IRTranslator介绍
IRTranslator 是全局指令选择第一阶段的第一个Pass,主要的功能是将LLVM IR转换为GMIR代码。它使用的指令转换算法是宏展开算法,每次转换一条LLVM IR。因为GMIR的操作码(Opcode)具有通用性,LLVM IR也是架构无关的中间表示,所以大部分LLVM IR指令转成GMIR指令的实现都是架构无关的,另外,GMIR还包含一些目标架构相关的信息,例如函数调用约定处理,需要将这一部分LLVM IR转换成架构相关的GMIR(在实现层面不同的目标架构需要各自实现这部分代码)。如图7-28所示,IRTranslator的实现可以分为架构无关和架构相关两部分,像算术运算、逻辑运算等指令的转换都是架构无关的;而像形式参数处理、函数调用等就是架构相关的,因为它们必须要知道目标架构的调用约定才能处理。
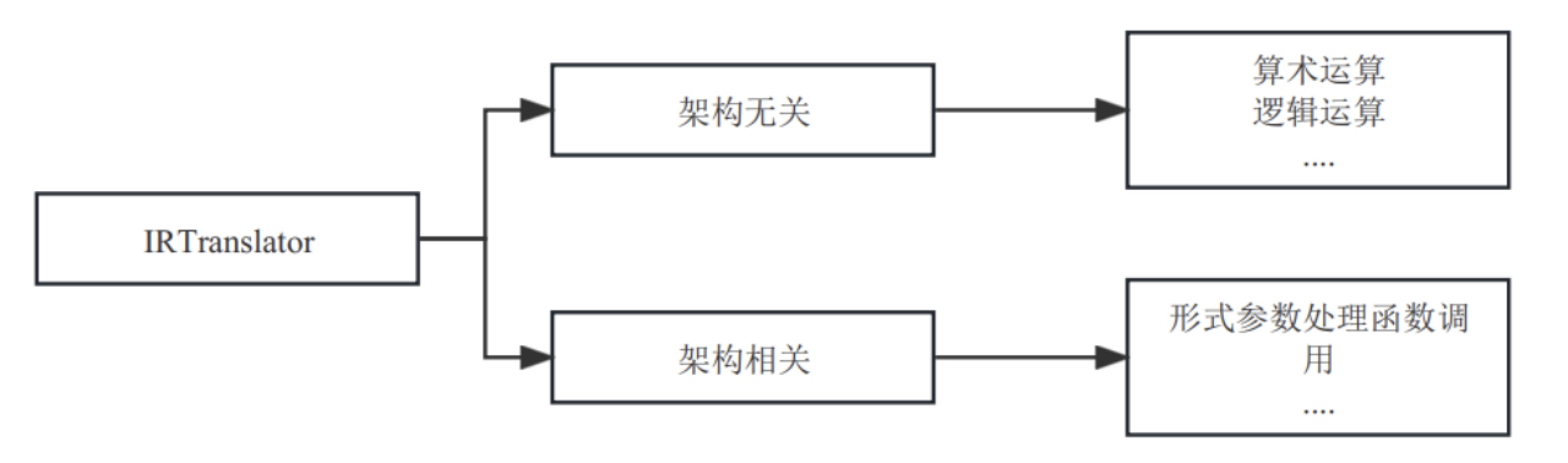
图7- 28 IRTranslator实现概览图
上面简单介绍了IRTranslator的基本功能,下面介绍IRTranslator的执行过程。IRTranslator的执行过程是以函数为粒度进行的(和SelectionDAGISel是以基本块为粒度不同),由于函数可以分为函数头(形参信息)和函数体,函数体又有基本块等表示,所以我们按处理的函数信息不同,将执行过程分为4个主要的阶段:
1)基本块创建:这个阶段会遍历函数的LLVM IR基本块,依次为每个基本块创建对应的GMIR的基本块(后续根据指令情况,还可能会添加新的基本块),并且会保留相关的控制流信息,形成初始的控制流图。还会为每个函数添加一个额外的基本块(EntryBB),作为函数入口。
2)形参处理:根据目标架构的调用约定规则处理函数的入参,为每个入参生成一条从传参寄存器拷贝到虚拟寄存器的GMIR复制指令、或者为入参生成一条从栈上加载到虚拟寄存器的 GMIR加载指令,并将生成的指令放入EntryBB 中。
3)函数体指令转换:按RPOT(逆后序遍历)的方式遍历函数的控制流图,对于每个基本块,以自顶向下的顺序将基本块里的每条指令转换成一组GMIR指令。
4)控制流图更新:在上述第 3 阶段指令转换过程中,有些原本不是跳转的指令会被翻译成跳转指令(如,跳转指令的条件码是由多条连续的逻辑运算指令生成的,此时就有可能会拆分逻辑运算生成多个跳转指令),导致原有基本块被拆分出多个新基本块,破坏了原有的控制流。因此在基本块指令转换好后,需要维护好这些新基本块与原有基本块的控制流边,形成新的控制流图。此外,还可能会将EntryBB和函数体中的第一个基本块合并,此时控制流信息也要跟着更新。
下面通过例子来具体演示下4个阶段的功能。例子源码如代码清单7-16所示。
IRTranslator示例源码
1 | return a + b; |
经过以下命令编译:clang –target=Aarch64 -S -mllvm –global-isel -O2 7-16.c可以得到IRTranslator处理前的IR,如代码清单7-17所示。
代码清单7-16源码对应的IR
1 | entry: |
1.基本块创建
首先会建立一个EntryBB作为存放入参处理指令的基本块,记为bb.0,如代码清单7-18所示。
创建基本块EntryBB
1 | bb.0: |
接着处理函数的基本块,由于该函数只有一个基本块,所以只需要建立一个GMIR基本块,记为bb.1.entry,如代码清单7-19所示。
创建基本块bb.1.entry
1 | bb.0: |
2.形参处理
首先,为形参创建虚拟寄存器,本例中有2个形式参数,所以创建了两个虚拟寄存器%0和%1。然后,根据目标架构的调用约定(ABI),生成拷贝指令或者加载指令。当前是Aarch64后端按照其调用约定,在bb.0中生成2条从物理寄存器到虚拟寄存器的COPY指令,如代码清单7-20所示。
形参处理
1 | Function Live Ins: $w0, $w1 |
3.指令转换
以PROT遍历函数的每个基本块,进行指令转换。这个例子中有两条指令需要转换,分别是add和ret指令。
add指令展开成一条G_ADD指令即可(G_ADD是GMIR中定义的加法操作,和LLVM IR中add指令对应)。先将两个源操作数转为虚拟寄存器,然后创建一个目的操作数的虚拟寄存器,最后三个虚拟寄存器和G_ADD操作码组成一条GMIR加法指令,如代码清单7-21所示。
源操作数处理
1 | Function Live Ins: $w0, $w1 |
接着处理ret指令,需要展开成返回值处理指令和返回指令,此处根据目标架构调用约定判断将返回值放入物理寄存器或是栈上。首先获得返回值的虚拟寄存器,这里只有一个i32的返回值,根据Aarch64的调用约定,可以直接放入w0这个物理寄存器,所以只需要一条复制指令;然后再生成一条ret的返回指令。代码如清单7-22所示。
ret处理
1 | Function Live Ins: $w0, $w1 |
4.控制流更新
此用例没有额外新增基本块,不需要进行函数体控制流的调整。但是bb.0到下一个基本块(bb.1.entry)没有分支,所以可以将bb.0直接合并到下一个基本块,最后得到GMIR如代码清单7-23所示。
控制流生成
1 | Function Live Ins: $w0, $w1 |
7.4.3 Legalizer介绍
经过IRTranstor的转换,以LLVM IR表示的函数已经变成了GMIR表示的函数。虽然,IRTranstor转换后引入了部分架构相关的信息,但是大部分转换生成的GMIR指令还是架构无关的,因此部分GMIR指令对于目标架构而言会存在不支持的情况。比如,对于一个16位字长的目标架构,无法直接表示单条64位加法,如果IRTranstor生成了64位GMIR加法指令,则对于16位字长的目标架构就是非法指令。为了处理非法GMIR 指令,全局指令选择实现了一个独立的Pass(Legalizer Pass,合法化)。这个Pass会引入目标架构相关的指令信息,根据这些指令信息,将函数中非法的GMIR指令一一替换成合法的GMIR指令(即目标架构可以支持的指令)。
Legalizer的处理过程也是以函数为粒度进行的,按RPOT的方式从函数入口开始依次遍历函数中的每个基本块,在基本块中自顶向下地遍历指令,逐条识别指令是否为非法指令,如果发现非法指令会将其转换为合法指令,直到将所有的非法指令都转换为合法指令后,Legalizer工作就结束。
Legalizer的处理过程实际上包含了两个关键子问题的处理,分别是:
- 非法指令识别问题:判断一条GMIR指令是否是非法指令。
- 非法指令转换问题:将一条非法的GMIR指令转换成一条或者一组合法的GMIR指令。
Legalizer的工作流程也比较简单,输入是函数初始的GMIR(由IRTranslator生成,或者手写),然后经过非法指令识别和非法指令合法化两个阶段的处理,最终生成合法的GMIR。
1.非法指令识别
Legalizer识别非法指令的基本原则是:非法指令存在寄存器操作数的数据类型是目标架构寄存器无法直接表示的情况(直观上看就是一个寄存器操作数无法被一个目标架构的寄存器表示)。例如,如果目标架构有64位的加法指令,则64位的GMIR加法指令是合法的;反之则是不合法的。依据这个原则,每个架构都会根据自己的指令集信息,设置每个 GMIR Opcode 在哪些类型是合法的,同时给出不合法类型指令转换成合法指令的方式。所以当一个目标架构指令集确定后,就可以设置每个GMIR Opcode的合法化属性,根据这个属性,就可以判断出一条GMIR指令是否合法,以及不合法时需要选择的合法化操作。目前合法化属性有如下12种:
- Legal:表示指令已经是合法的,无需操作。
- NarrowScalar:以多个较低位数的指令来实现一个较高位数的指令。
- WidenScalar:以一个较高位数的指令来实现一个较低位数的指令(将高位丢弃)。
- FewerElements:将向量操作拆分成多个小的向量操作。
- MoreElements:以一个较大的向量操作来实现一个小的向量操作。
- Bitcast:换成等价大小的类型操作。
- Lower:以一组简单的操作实现一个复杂的操作。
- Libcall:通过调用库函数的方式来实现操作。
- Custom:定制化。
- Unsupported:操作在后端架构上无法支持。
- NotFound:没有找到对应的合法化操作。
- UseLegacyRule:适配老版本合法化的选项。
2.非法指令合法化
主要的思路就是将非法GMIR指令替换掉,可以分为三类处理方式:
- 将不合法指令类型向上扩展或则向下拆分,用一组新的GMIR替换掉原来的GMIR。
- 通过调用lib库函数的方式来实现非法GMIR指令的功能。
- 由目标架构进行定制化实现,直接替换成一组MIR指令。
3.Legalizer示例分析
下面以代码清单7-5中的加法计算为例子来说明Legalizer的基本过程,目标架构是 Aarch64。代码中进行16位的加法计算,而目标架构 Aarch64 后端整型寄存器只有支持 32 位和64位的,所以IRTranslator之后多了一些类型转换指令(Trunc、ANYEXT),具体GMIR如代码清单7-24,作为Legalizer的输入。
Legalizer示例源码对应的GMIR
1 | Function Live Ins: $w0, $w1 |
首先Legalizer会过滤掉不需要处理的指令(伪指令或者架构相关的指令,如上例中的COPY指令,RET_ReallyLR指令)。对于需要处理的指令,会按类型转换指令和实际指令两类进行区分开处理。只有实际指令有合法要求,类型转化指令只需要合并消除,所以两者的处理是不同的。实际指令指的是真实功能指令,例如例子中的G_ADD指令“_(s16) = G_ADD %1:, %0:”就是一个真实的指令;类型转换指令用于处理类型的扩展或者降低,例如代码7-24中的“%0:(s16) = G_TRUNC %2:(s32)”和“%5:(s32) = G_ANYEXT %4:(s16)”分别是将32位数据类型降低到16位数据类型、16位类型提升到32位数据类型。
(1)实际指令处理
对于每个实际指令,Legalizer会获取它的合法类型,然后按照类型进行处理。代码7-24只有一条实际指令add,因为它是16位的加法,在Aarch64里是不合法的加法,Aarch64支持32位加法,所以它的合法类型是WidenScalar,向上提升类型,变成32位加法指令。
具体的操作是使用扩展指令扩展每个源操作数位到32位,然后使用截断指令将新得到的32位目的操作数截断到原来的16位操作数上,得到的指令如代码清单7-25。
16位加法运算合法化处理后的GMIR
1 | Function Live Ins: $w0, $w1 |
当然由于新增加的32位加法指令,新增指令也会被放入工作列表中,进行合法化处理。由于32位加法Aarch64是支持的,所以它的合法类型是Legal,不需要处理。
(2)类型转换指令处理
可以看出代码7-24中多了许多类型转换指令,有些是冗余的。如先G_TRUNC再进行G_ANYEXT这种模式就是无效的操作。例如代码清单7-26中的代码。
先G_TRUNC再G_ANYEXT
1
%6:_(s32) = G_ANYEXT %1:_(s16)
首先将32位类型截断至16位类型,再将16位类型提升至32位类型,实际上就是冗余操作,可以进行合并。合并删除掉这些冗余指令后,得到的合法化的输出,7-25类型合法化后得到的结果如代码清单7-27。
冗余指令优化后
1 | Function Live Ins: $w0, $w1 |
7.4.4 RegBankSelect介绍
虽然Legalizer引入了目标架构指令信息,将IRTranslator生成的GMIR变成了目标架构合法的GMIR,但可以发现Legalizer后的GMIR指令仍然是没有目标架构寄存器信息。指令里的虚拟寄存器操作数只有一个数据类型,用于表示它的类型(指针、标量还是向量)和它的位数大小。比如指令“%2:(s32) = nsw G_ADD %1:, %0:_”中操作数%2只有一个s32类型,表示它是一个32位标量的虚拟寄存器操作数。而一个32位标量的虚拟寄存器操作数,在特定的目标架构上可能会有多种寄存器类型表示它,例如可以是32位的整型寄存器类型,也可以是32位的浮点寄存器类型。然后这两种又可以根据使用场景不同进行细分,如32位整型寄存器类型可以分为32位整型通用寄存器类型和栈指针类型等。由于没有为32位标量的虚拟寄存器操作数确定一个寄存器类型,G_ADD这条指令无法确定后续可以使用的物理寄存器。所以,全局指令选择模块需要给IRTranslator生成的GMIR分配寄存器类型的功能,即RegBankSelect。
RegBankSelect是全局指令选择模块的第三个基本Pass,它会利用目标架构的寄存器信息,为合法化后的GMIR指令中的虚拟寄存器操作数分配合适的寄存器类型,并且它还可以利用GMIR指令之间的关系选取一个较优的寄存器类型。这也是为什么不直接在IRTranslator处理中为GMIR指令生成直接分配寄存器类型的原因之一,在IRTranslator生成指令时,LLVM IR还没有全部转换成GMIR,无法利用指令之间的关系进行寄存器类型择优。在RegBankSelect阶段之后,每个虚拟寄存器操作数就有对应的寄存器类型了,如上述例子中的G_ADD指令变为“%2: gpt(s32) = nsw G_ADD %1:gpr, %0”。下面来看看RegBankSelect的实现原理。
RegBankSelect处理方式和Legalizer类似,它也是以函数为粒度进行,并按RPOT的方式从函数入口开始依次遍历函数中的每个基本块,然后在基本块中自顶向下遍历指令,给每一条指令的每个虚拟寄存器操作数分配寄存器类型。寄存器类型分配好后,就重写指令,为指令的每个虚拟寄存器操作数填上相应的寄存器类型。当然,可能会出现给一个虚拟寄存器操作数分配的寄存器类型和它定义点指令分配的类型不一致,这个时候要重新生成一个新类型的虚拟寄存器操作数,替换掉指令原来的虚拟寄存器操作数,并插入一条COPY指令将原来的虚拟寄存器操作数复制到新寄存器类型的虚拟寄存器操作数。指令重写完成后,一条指令的寄存器类型分配就完成了。然后继续下一条指令的寄存器分配直到函数中每条需要分配寄存器类型的指令都完成了寄存器类型分配,RegBankSelect整个过程就完成。
RegBankSelect将上述功能划分成了三个子模块,分别是寄存器类型管理模块、寄存器类型分配模块和指令重写模块。
1.寄存器类型管理模块
这个模块用于管理RegBankSelect阶段引入的目标架构寄存器类型信息,并提供通过数据类型获取寄存器类型。此处GMIR新增了一个新的寄存器类型概念——RegBank,它比MIR的RegisterClass寄存器类型概念更粗粒度,只会对目标架构寄存器进行一个简单的划分,因此一个RegBank表示的寄存器类型可能会对应一到多个RegClass表示的寄存器类型。以Aarch64架构的寄存器信息为例,如图7-29所示,RegBank表示的寄存器类型只被分为三类;而RegisterClass表示的寄存器类型则超过了十几种类型(目前代码中共有46类)。
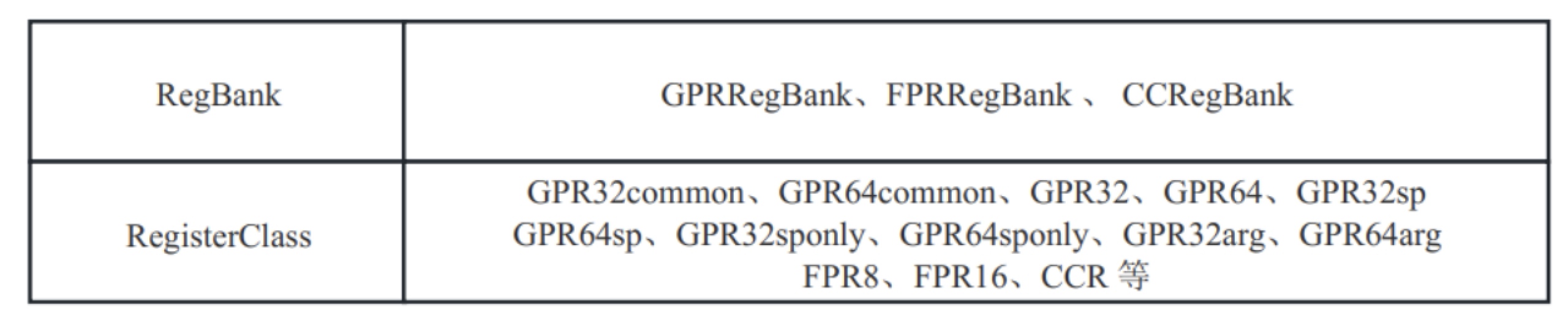
图7- 29 Aarch64寄存器分类示意图
RegBankSelect不直接使用RegisterClass的原因是GMIR和MIR对于寄存器类型的要求是不同的。GMIR期望寄存器类型简单,这样可以做到相对架构无关,能够匹配与架构无关的GMIR Opcode,避免因为寄存器类型限制住GMIR指令可转换成的MIR指令类型,保证后面生成的MIR指令质量;而MIR的指令基本都是架构相关的,不同指令使用的寄存器可能是不相同的,因此需要更细致的寄存器类型,保证指令的寄存器操作数使用的寄存器类型包含的寄存器都是指令可用的。故而,通过新增RegBank来表示GMIR的寄存器类型,解决了 GMIR与MIR的需求矛盾。本节中的“寄存器类型”都特指的是RegBank表示的类型。
2.指令寄存器操作数类型分配模块
这个模块利用寄存器管理模块中的寄存器类型信息,为每条GMIR指令的虚拟寄存器操作数分配寄存器类型。每条GMIR指令完成寄存器类型分配后,指令就会有一个与之对应的寄存器类型组,这个寄存器类型组中的寄存器类型与指令的虚拟寄存器操作数是一一对应的。如上述的G_ADD指令经过分配模块之后就会有一个关联的寄存器类型组(gpr,gpr,gpr),三个虚拟寄存器都被分配了gpr的类型。
为了适配编译器的不同优化场景,这个模块实现了两种分配算法:
- Fast:只寻找指令的默认可用的寄存器组合,所以运行时间快。
- Greedy:它会先寻找指令的默认可用的寄存器组合,然后再找目标架构额外允许的其他所有可用组合,最后计算每个组合的成本,选出一组成本最低的组合。
3.指令重写模块
具有虚拟寄存器操作数的GMIR指令经过寄存器类型分配模块后,就有一组寄存器类型,然后指令重写模块会根据这组寄存器类型,重写GMIR指令,逐个对寄存器操作数判断是否有寄存器类型,如果没有则直接填上对应的寄存器类型。否则,判断寄存器类型是否一致,一致则不变;不一致就需要根据寄存器组里寄存器的类型生成一个新寄存器操作数,然后替换指令中原有的操作数,并生成一条旧操作数到新操作数的拷贝指令。
4.RegBankSelect示例分析
下面结合一个简单的用例详细阐述RegBankSelect整个流程和各个模块的功能,用例源码见代码清单7-28。
RegBankSelect示例源码
1 | return a | b; |
以Aarch64为目标架构,经过前面的编译到Legalizer之后的GMIR如代码清单7-29。
RegBankSelect示例源码对应的GMIR
1 |
|
代码7-29里有三个变量%0,%1,%2需要分配寄存器类型。首先需要知道Aarch64里有哪些寄存器组可以用?在Aarch64里根据数据类型不同进行区分,定义的寄存器组有三个分别用于表示:整型,浮点和标志寄存器。因为没有区分数据大小,所以不同数据大小的虚拟寄存器只要数据类型相同就可以使用同一种寄存器组进行表示,比如,GPRRegBank可以表示32位和64位的整型寄存器。对应的TD定义如代码清单7-30。
1 | /// 通用目的寄存器: W, X. |
代码7-29中的三个虚拟寄存器都是s32类型的,它可以被映射到GPRRegBank,也可以被映射到FPRRegBank,所以接下来要确定每个虚拟寄存器具体可以使用的类型。由于虚拟寄存器类型是按指令为粒度确定的,即每次确定一条指令里所有虚拟寄存器的寄存器类型,故接下来依次处理每条指令。此处获取寄存器组合有Fast和Greedy两种方式,因为Greedy基本包含了Fast的过程,这里仅演示Greedy的处理方式。
第一条指令%0:(s32) = COPY $w0
此条指令是COPY指令,它将一个整型物理寄存器$w0拷贝到%0上。先去查找它的默认寄存器类型组合,由于它的源操作数是整型,所以默认的寄存器类型组合是GPRRegBank。然后因为Aarch64没有COPY指令相关的额外寄存器类型组合的处理,所以只有一种寄存器类型组合。再接着计算指令使用GPRRegBank的成本,由于只有一组组合,故它就是最优的。最后改写指令,给指令的%0操作数赋上GPRRegBank类型。得到的结果为:%0:gpr32 = COPY $w0。
第二条指令%1:(s32) = COPY $w1
此条指令也是COPY指令,步骤同上,也选择的是GPRRegBank,改写指令之后的GMIR为:%1:gpr32 = COPY $w1。
第三条指令%2:_(s32) = G_OR %1:gpr32, %0:gpr32
此条指令是G_OR指令,由于它的两个源操作数%0和%1在前面已经被分配为GPRRegBank,因此找到的默认寄存器组合如下,三个均为整型寄存器。即为:%2:GPRRegBank, %1:GPRRegBank, %0:GPRRegBank。
然后,因为Aarch64 具有“整型或”指令也具有“浮点或”指令,所以也给 G_OR 指令提供了两种额外的寄存器类型组合,分别表示整型和浮点的寄存器,具体如代码清单7-31所示。
GPRRegBank和FPRRegBank
1 | %2:FPRRegBank, %1:FPRRegBank, %0:FPRRegBank |
因此,合在一起共计有三种寄存器使用组合,其中第一种和第二种是相同的。接着依次计算每一种的成本,此处有一个计算公式:
Cost(寄存器组合) = LocalCost * LocalFreq + NonLocalCost,其中LocalCost的计算方法为:LocalCost = Cost(当前指令) + Cost(拷贝指令)* 新增拷贝指令数。
其中,LocalFreq表示指令所在基本块的Frequence(参见第2章控制流介绍),而NonLocalCost表示导致其它基本块产生拷贝指令的开销。并且Aarch64设定“或”指令的成本为1,浮点到整型拷贝指令的成本为4,当前基本块的Frequence为8,NonLocalCost为0(三种组合都没有在其它基本块产生拷贝指令)。根据这些公式和指令信息,我们可以计算出上述三种组合的成本分别是8,8,72,详细计算过程代码清单7-32所示。:
Frequence计算
1 | 8 * 1 + 0 = 8 |
所以第一种的成本最低,使用第一种寄存器组合改写指令,得到GMIR为:%2:gpr32 = G_OR %1:gpr32, %0:gpr32。
第四条指令$w0 = COPY %2:gpr32
此条指令也是COPY指令,源操作数%2已经确定寄存器类型,且目的操作数是gpr32类型的物理寄存器,所以无需任何操作。
当上面4条指令都改写好后,虚拟寄存器都赋上了类型。经过RegBankSelect后得到的GMIR如代码清单7-34所示。
RegBankSelect后得到的GMIR
1 |
|
7.4.5 InstructionSelect介绍
经过了全局指令选择第一阶段(IRTranslator、Legalizer和RegBankSelect)处理后,LLVM IR已经被转换成合法的(目标架构支持的)GMIR,并且具有了调用约定、寄存器类型等目标架构相关的信息。接着就可以进行第二阶段的工作,将GMIR转成目标架构相关的MIR。第二阶段的工作由一个Pass实现的,即InstructionSelect。经过InstructionSelect处理后,整个全局指令选择工作就完成了,后续的Pass都是基于MIR进行分析和优化(寄存器分配、指令调度和窥孔优化等)。下面我们简单介绍一下InstructionSelect的基本原理和过程。
InstructionSelect是以函数为粒度进行指令选择,使用的是基于树覆盖的指令选择算法。目前实现了两种树覆盖的方式,一种是基于表驱动的自动状态机进行的自动覆盖方式;另一种是基于固定模式的手动覆盖方式。这两种覆盖方式每次覆盖的时候都只会产生一种成功匹配的树模式,因此可以直接生成对应的MIR指令序列。InstructionSelect功能可以划分为三个模块。
- 自动匹配模块:构建状态机,并利用自动状态机生成指令可以匹配的树模式。
- 手动匹配模块:目标架构会有内置一些固定的树模式,遍历内置的固定树模式,判断是否指令可以匹配其中的一个树模式。
- 指令生成模块:根据指令匹配上的树模式生成对应的MIR指令序列。
下面看一下InstructionSelect执行过程。首先,对于一个给定函数的GMIR,它会按逆序的方式从函数底部开始依次遍历函数中的每个基本块,在基本块里自底向上处理每一条 GMIR指令。然后,对于一条待处理的GMIR指令,先判断它是否已经生成过MIR指令,如果已经生成则不再处理,否则就以这条指令为根节点执行上述的自动匹配模块和手动匹配模块,进行树覆盖匹配。匹配成功后就生成MIR指令,否则报错。最后,迭代执行直到报错或者所有的GMIR指令都被转换成功为止。
在模式匹配过程中,自动匹配模块和手动匹配模块都可以生成MIR指令,但是只需要一个生成MIR指令即可。两个模块的执行顺序是由目标架构设定的,比如Aarch64中会将手动匹配模块里的模式拆分,形成两个子模块,构成如图7-30所示的执行顺序,先执行手动匹配模块一,如果匹配不成功再执行自动匹配模块,如果还匹配不成功就再执行手动匹配模块二。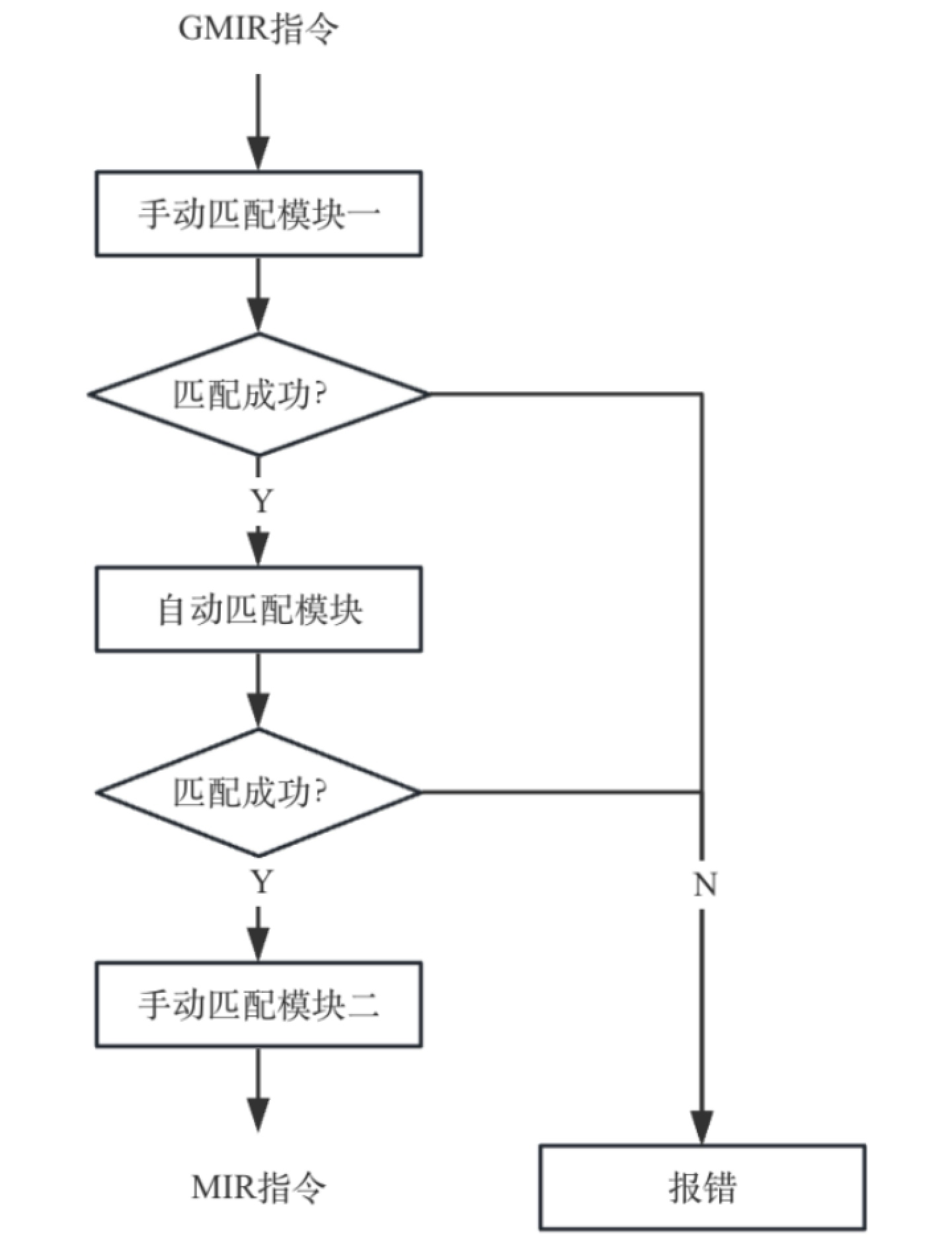
图7- 30 Aarch64全局指令选择中指令匹配流程图
1.自动匹配模块
自动匹配模块分为2个阶段,第一个阶段是构建自动匹配状态机,它是在编译器生成的时候由TableGen构建的;第二阶段是使用自动匹配状态机,这是在全局指令选择InstructionSelect模块里使用的。整个构建和使用的过程和SelectionDAGISel里的自动匹配状态机是一样的,因此可以参考上一节的介绍,此处不在赘述。本节主要介绍下全局指令选择在TD文件中定义的一个新记录─GINodeEquiv,如代码清单7-34所示。
全局指令选择在TD中定义的记录GINodeEquiv
1 | Instruction I = i; |
记录GINodeEquiv是为了减少从SelectionDAGISel迁移到全局指令选择的工作量而定义的,通过它可以将TargetOpcode和SelectionDAGISel的ISD Opcode关联起来,从而可以复用对应 ISD Opcode的Pattern。例如,要复用Aarch64在SelectionDAGISel加法指令的模式,可以把G_ADD和对应的ISD Opcode─add关联起来,如代码清单7-35所示。
把G_ADD和add关联
1 |
然后TableGen就可以根据add的Pattern来获得G_ADD的Pattern,从而生成相应的匹配状态机。
2.手动匹配模块
手动匹配模块会将可以用于匹配的树模式一一通过手动编写某些TargetOpcode匹配上目标架构指令的过程,因此树模式都是固定的。它们需要目标架构各自客制化的实现在目标架构相关的文件里。通常都是TD无法配置的树模式需要手动编写,如多输出的指令模式,或者需要手动选择才能最优的树模式。当然,如果在开发过程中觉得Pattern不容易理解的,也可以先全部手写函数来实现匹配过程。手写匹配模块中的树匹配模式放到自动匹配之前调用,还是在它之后调用,通常是根据是否能生成比较优异的代码指令进行抉择的。
以当前Aarch64为例,它在自动选择之前只对7 Opcode(G_DUP、G_SEXT、G_SHL、G_CONSTANT、G_ADD、G_OR、G_FENCE)的一些场景进行了手写生成。其中G_CONSTAN在立即数为零的时候,手写会生成一条从零寄存器(XZR、WZR)拷贝的指令,否则就回到自动匹配的流程上,其它的Opcode也是类似的处理过程。但自动选择之后,会对许多特殊的Opcode(如G_PTR_ADD、G_SELECT、G_VASTART等)都提供手写匹配的过程,保证它们都可以匹配上。
7.4.6 合并优化介绍
在完成了上述4个Pass之后,已经可以将LLVM IR转成MIR。对于汇编代码生成质量要求不高的场景,只要目标架构有这4个Pass就够了。但是对于性能要求高的场景,可以发现只有上述4个Pass生成的代码质量还是不够的。之所以会有代码质量的问题,是因为全局指令选择本质上还是一个在图上的(函数本身是一个图)基于树匹配的模式匹配算法,它是无法处理共用节点、多输出和控制流等具有图属性的场景,比如两个树共用的多输出的节点,全局指令选择只能将其当成两个树分别处理,对于共用节点进行复制处理,此时就会产生冗余指令,影响了代码生成质量。因此,全局指令选择允许在每个基础Pass之后,添加一个或多个合并优化Pass,通过这些优化Pass优化掉树匹配无法处理的指令模式,从而产生质量更高的汇编代码。
全局指令选择提供了一个优化调用框架,它大致可以划分为三个部分:基础设施,优化模式匹配规则和优化模式重写。
- 基础设施:主要实现了待优化GMIR指令的遍历以及所有可以优化模式的管理。
- 优化模式匹配规则:定义了每个优化模式的匹配规则,对于特定的优化模式,待优化指令需要满足它的规则,才能使用这个优化模式。
- 优化模式重写:将待优化的指令改写成特定优化模式对应的指令序列。
其中基础设施代码,以及一部分通用优化模式的匹配实现是架构无关的。而特定目标架构的优化Pass可以实现自己的优化模式,并且可以选用上述公共的优化模式。
合并优化Pass的优化过程是基于工作表(worklist)的算法,目标架构将它可以做合并优化的指令都放入worklist中,然后遍历worklist为每条指令选择可以做的合并优化,优化做完后将新产生的指令放入worklist中,依次迭代直到没有新指令产生,worklist为空则优化结束。
特定目标架构实现的优化Pass可以选择基于上述的worklist算法进行的,这样不同优化Pass之间的区别只是使用的优化模式不同;也可以直接基于Pass框架自行实现待优化指令的遍历和相应的优化过程。因为添加的合并优化Pass数量和位置,以及每个Pass的合并优化类型都是架构相关的,所以下面我们以Aarch64为参考,研究下特定目标架构的合并优化Pass的大致配置情况。
全局指令选择在Aarch64架构上共有10个Pass,除了4个基础Pass,还有6个优化Pass。这6个优化Pass有2个在IRTranslator之后执行,2个在Legalizer之后执行,1个在RegBankSelect之后执行,还有1个在InstructionSelect之后执行,具体如图7-33所示。当不开优化的时候只执行图7-33中的基础Pass,开启优化后,就会执行图7-33中的优化Pass。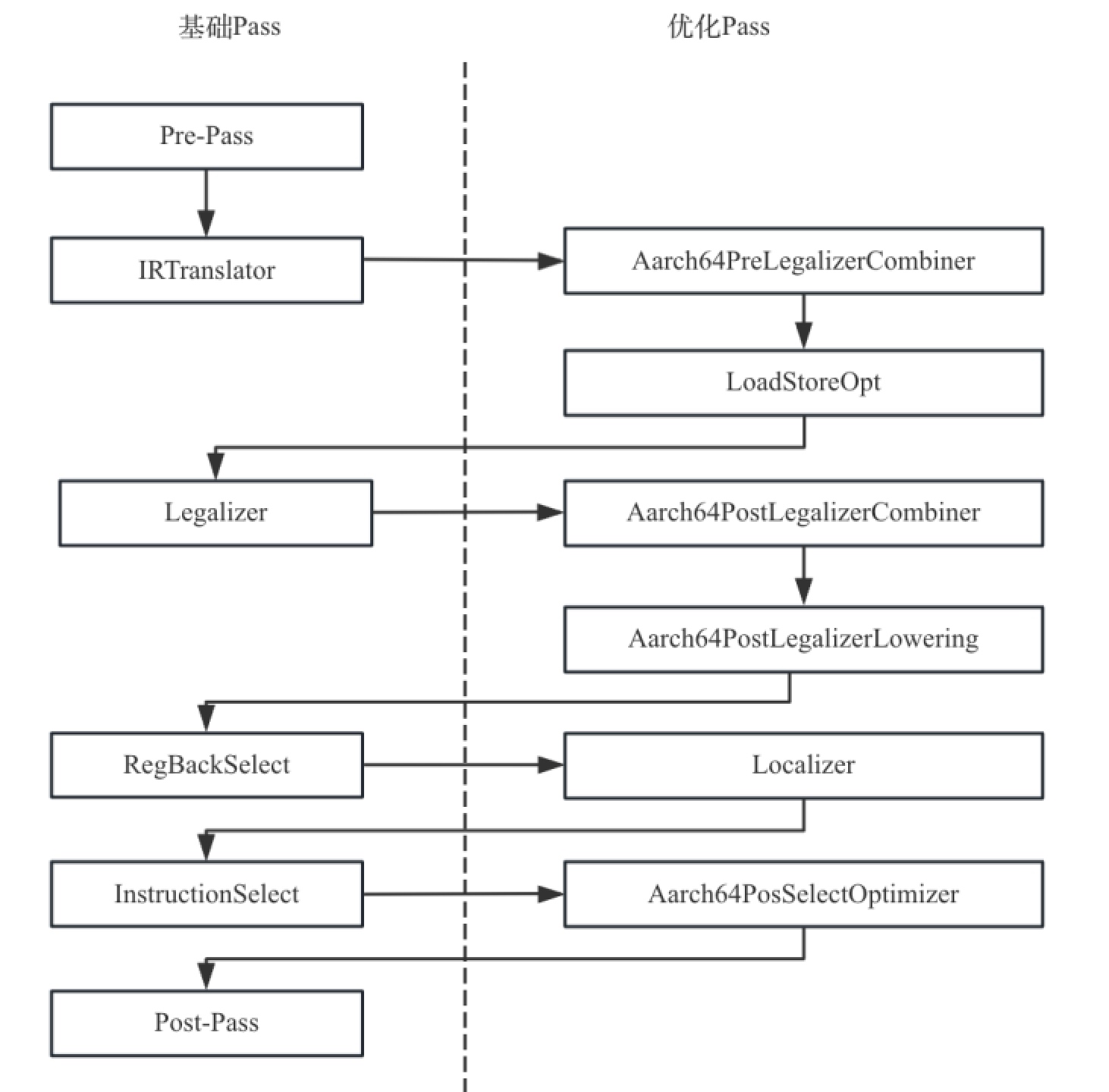
图7- 31 Aarch64指令选择全部Pass示意图
下面我们简单介绍6个优化Pass的工作。
1)Aarch64PreLegalizerCombiner,它是基于worklist优化框架的,自己实现了三个主要的优化模式,还有一些小优化不再一一列举。此外,它还使用了公共的一些优化模式。
表7-1 合法化前的指令合并优化
优化模式 原始指令 优化后指令
将向量指令转为标量指令 G_FCONSTANT G_CONSTANT
消除冗余的G_TRUNC G_ICMP(G_TRUNC, 0) G_ICMP(reg, 0)
全局地址偏移折叠 G_GLOBAL_VALUE/G_PTR_ADD G_GLOBAL_VALUE
2)LoadStoreOpt,它是基于Pass框架的优化,遍历函数的每条指令,针对Store指令,将多条Store指令合并成一条Store指令的合并优化。
3)Aarch64PostLegalizerCombiner,它是基于worklist优化框架的,本身实现了五种优化模式,分别是 G_EXTRACT_VECTOR_ELT、G_MUL、G_MERGE_VALUE、G_ANYEXT 和 G_STORE 这五类指令的优化,此外,还使用了一部分公共优化模式,由于优化模式太多就不再一一展开介绍。
4)Aarch64PostLegalizerLowering,它是基于worklist优化框架的,实现了十四种优化模式,主要针对 G_SHUFFLE_VECTOR、G_EXT、G_ASHR、G_LSHR、G_ICMP、G_BUILD_VECTOR 和 G_STORE 这六类指令进行优化。
5)Localizer,它是基于Pass框架的优化,主要是移动指令,让其尽可能地靠近它的第一个使用点,从而缩短寄存器的生命周期。
6)Aarch64PostSelectOptimizer,它是基于Pass框架的优化,主要是简化浮点比较指令的使用。
通常来说,对于一些简单的优化,都是将其表示成模式,然后通过通用框架直接完成优化;而比较复杂的优化,都是直接通过自行编写Pass遍历过程完成的。
通过上述的介绍可以看出,全局指令选择将SelectionDAGISel耦合在一起的功能提取为多个独立的Pass,实现了高内聚低耦合的设计;同时,GMIR的引入,既避免DAG IR和MIR因语法形式差异大需要的转换成本,又因为它与MIR共用基础设施数据结构,进一步降低了代码维护的成本。当然,因为全局指令选择的诞生时间还比较短,还不够完善,生成的汇编代码质量不如SelectionDAGISel,且当前支持的目标架构也不丰富。因此,全局指令选择还需要各个目标架构进一步开发和完善。