第2章 MLIR-设计、实现与架构 [TOC]
MLIR作为一款编译器框架,提供了许多功能,包括:如何定义IR,包括操作、操作与之关联的类型、操作上的属性,并通过方言进行管理这些信息。另外MLIR框架中还包括针对IR中操作的优化,多级IR之间的转化,编译过程的中调试功能等功能。这些功能为MLIR的成功提供了基础。本章主要介绍MLIR涉及到的各种概念,主要包括:
2.1MLIR的组成与结构 MLIR的IR是一种编译器的中间表示,它非常类似于传统SSA形式的三地址码,同时它又引入了针对循环的多面体优化表述形式。通过MLIR框架可以完成代码表示、分析、优化、和高性能目标代码生成。
2.1.1操作 操作(Operation)是MLIR中最基础的单元,它的含义也非常丰富。例如用操作表述高级语义时,一个操作可以是函数定义、函数调用、缓存区分配、缓存区切片,甚至是进程创建等;用操作表述低级语义时,一个操作可以是目标架构无关的算术运算、目标架构相关的指令描述、寄存器信息、电路信息。MLIR相关工作基本上都是围绕操作展开的。
2.1.2类型 操作总是有与之关联的数据类型(Type),例如matmul处理矩阵类型(记为Tensor),可以是二维、三位甚至是多维的。
2.1.3属性 开发者在定义操作和类型时,可以为它们添加属性(Attribute),用于指定操作或者类型额外的信息。例如上面的类型Tensor<2 x 3 x f32>表示一个矩阵,但是在一些场景中矩阵中大多数元素为0,那么可以对矩阵进行压缩存储,一种自然的想法是为Tensor<2 x 3 x f32>增加一个属性,用于表示压缩格式(当然针对矩阵压缩有很多压缩方式,在第10.2.7节稀疏张量还会进一步介绍)。例如Tensor<2 x 3 x f32, encoding>这里的encoding就是各种不同的压缩方式。
2.1.4方言 由于开发者可自由定义操作、以及与操作关联的类型、属性,每个操作操作都是一个IR。为了更好管理自定义IR,MLIR框架提供了方言机制(Dialect),对操作、属性、类型进行管理(方言有点类似容器或者命名空间的概念)。通过方言机制,可以将同一层次抽象出来的操作、类型和属性放在具体的方言中,这样的方言称为一层IR。
1 2 3 4 5 ^block(%block_argument : !argument_type): "dialect.further_operation"() [ ^successor ]:() -> () ^successor: ... }) : (!operand_type) -> !result_type<"may_be_parameterized">
这段IR的解释如代码2-2所示。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 //其中dialect为方言名,operation为操作名 //操作接受参数为value_use,并且操作有一个属性,名字为attribute_name //属性值为attr_kind<"value">,属性的结构为key-value对形式 //操作的输入类型即value_use的类型是operand_type //operand_type前面的!表示operand_type为自定义类型 //操作的输出类型为result_type<"may_be_parameterized"> %value_definition = "dialect.operation"(%value_use){ attribute_name = #attr_kind<"value"> }({ // 这里的{定义了区域,下面整个区域是操作的payload //区域包含了基本块.其中基本块是^开头定义的 //block表示基本块的名字,而block_argument是基本块参数,其类型为argument_type //在argument_type前面的!表示argument_type是开发者自定义的类型 ^block(%block_argument : !argument_type): //基本块又包括了操作,操作为dialect。further_operation //操作输入类型为void,输出类型为void //further_operation执行完后跳转到后继基本块successor "dialect.further_operation"() [ ^successor ]:() -> () //基本块successor的定义,它没有基本块参数 ^successor: //下面可能有更多的操作忽略 ... }) : (!operand_type) -> !result_type<"may_be_parameterized">
总结来说使用dialect.operation定义值value_definition可以供其它代码引用。而operation本身可以内嵌更多的操作,且内嵌需要按照一定的格式组织。
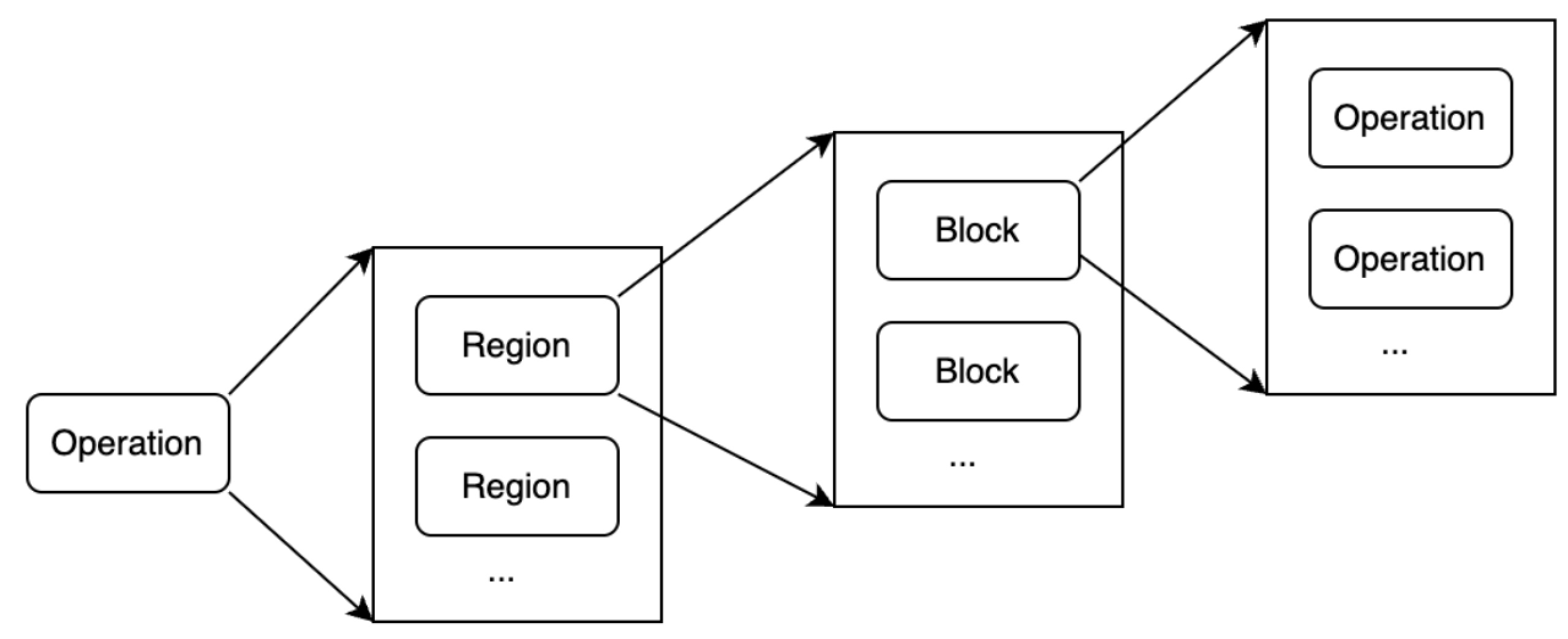
2.1.5IR结构 操作定了抽象的信息处理,但是操作本身还可以携带处理过程,表达处理过程的IR称为payload IR。MLIR的IR结构除了定义的操作外,还定义了区域(Region)和基本块(Block)2种基本单元。操作可以包含区域,区域又可以包含基本块,基本块又可以包含操作。这3种基本单元可以进行递归定义从而构成了IR的基础。如图2-1所示。
区域 在MLIR LangRef[ https://mlir.llvm.org/docs/LangRef/,2024年7月访问。]中提到区域是由一些基本块组成,基本块中包含了一些操作。但是并没有进一步明确操作执行的顺序。原因是区域是MLIR中特别引入的单元,目前有SSACFG和Graph两种区域[ MLIR中引入了区域导致了一些问题,目前社区正在讨论引入一种新的区域,但是目前尚未形成最后结论。https://discourse.llvm.org/t/rfc-region-based-control-flow-with-early-exits-in-mlir/76998,2024年7月访问。]。其中:
SSACFG区域:表示区域内的操作具有执行顺序约束,这个执行顺序和我们熟知的CFG完全相同。它可以由多个基本块组成。
Graph区域:区域内的操作并没有执行顺序约束,甚至一个使用的变量可以出现在其定义之前。它只能包含一个块[ 特别提示这里是说块而非基本块,原因是块里面的操作执行顺序和传统意义上基本块内执行顺序执行不一致。]。
基本块 基本块是由一组连续执行的操作组成,和传统的基本块定义基本一致(这里不讨论图区域中的块),但和传统基本块最大的不同之处在于MLIR中基本块接受参数(Block Argument,基本块参数),而不使用PHI指令(PHI表示不同执行路径的聚合点,同一变量在不同路径被赋值,在聚合点需要引入PHI指令,将不同路径的赋值变量通过PHI指令重新聚合为一个变量,从而满足SSA要求)。https://mlir.llvm.org/docs/Tutorials/UnderstandingTheIRStructure/, 2024年7月访问。]。
2.1.6存储格式与使用 MLIR在使用过程中提供了3种IR的描述方式,分别是:
文本格式:使用字符串格式定义IR,MLIR框架支持读取和解析字符串,并生成相应的对象;
内存格式:在MLIR编译时使用的内存对象;
字节码格式:便于传输的压缩格式。
2.2谓词、约束、特质和接口 MLIR使用谓词、约束、特质解决IR正确性保证。而正确性保证可以分为IR运行之前以及IR运行时两种,其中IR运行之前主要可以分为IR的解析和构建,因此可以IR正确性保证可以分为:
IR解析:保证IR格式正确,当定义错误的IR格式,在IR解析阶段就能发现错误。
IR构建:对于格式正确的IR可以构建出对象(例如操作、类型对象)。格式正确的IR但语义可能不符合IR的要求,MLIR框架应该有能力发现这样的错误。
IR运行时:保证构建的IR对象在运行时仍然具有某些正确性语义,满足运行时的约束。
2.3匹配、重写和Pass以及PassManager MLIR的设计围绕操作,提供其中一个重要的功能是以操作为核心的匹配、重写机制,这也是MLIR中转换的核心:针对操作进行匹配,并对可以匹配的操作提供重写新IR、替换或者删除旧IR的辅助能力。开发者只需要关注如何匹配操作(定义匹配规则),当操作匹配成功后关注如何替换操作、插入新的操作、删除旧操作等业务相关内容。
2.4调试 MLIR提供了丰富的调试功能,这也是MLIR能够成功的原因之一,典型的调试方法有四种:
2.5表描述语言及工具 MLIR作为LLVM项目的一部分,也使用TD描述操作、类型、方言等。由于MLIR在使用TD时有自己含义,所以MLIR框架提供了mlir-tblgen工具,将TD文件转转化为C++相关代码,mlir-tblgen工具在转化过程也分为两步:将TD转化为记录(Record)和将记录转化为C++代码,生成的C++可以和MLIR框架配合使用。
2.6其它公共功能 MLIR还提供位置追踪、文档生成、并行编译和Python交互等能力。
2.6.1位置追踪 操作的来源(包括其原始位置和变换后的位置)在编译过程中应该非常容易被追溯。这是为了解决在复杂编译系统中缺乏透明性问题,因为在复杂编译系统中,很难了解最终表示是如何从原始表示中构造出来的完整过程。在编译一些安全性至关重要的应用程序时,尤为突出。在这类程序中,跟踪降级和优化步骤是软件认证程序的重要组成部分。当使用安全代码(例如加密协议,或对隐私敏感的数据进行操作的算法)进行操作时,编译器常会碰到看似冗余或繁琐的计算,这些计算会嵌在源程序的功能语义中,可以防止暴露关键信息或加强代码安全以防止网络攻击或故障攻击。而准确地将高层次信息传播到较低层的一个间接目标就是帮助实现安全且可追溯的编译过程。
2.6.2文档生成 框架提供了自动文档生成功能,只要方言、操作、接口等定义时在TD中都会有概述(summary)、详细描述(description)、参数(parameter)、返回值(result)等信息,MLIR提供的mlir-tblgen可以直接抓取这些信息自动生成文档。这是非常典型的代码即文档的敏捷开发模式。
2.6.3并行编译 MLIR的一个重要需求是可以利用多核计算机来加快编译速度。Pass管理器支持并发遍历和修改中间表示,这可以通过操作的“与上方隔离(isolated-from-above)”属性提供的不变量来实现(该属性要求静态单赋值中的Use—Def链无法跨越这些操作的区域使用,即打断了Use—Def链),因此具有这种行为的操作定义了可以并行处理的区域。https://llvm.org/devmtg/2024-04/slides/Keynote/Amini-Niu-HowSlowIsMLIR.pdf,2024年7月访问。]。
2.6.4Python交互 为了方便Python开发者方便进行MLIR开发,在MLIR项目实现了Python和C++进行交互的模块,该模块依赖pybind11实现。关于Python和C++如何进行交互,以及如何使用pybind11,内容相对独立,本书不再进行介绍,读者可以参考其它文档学习。